")
")

"High Availability" Technology of Friktoria's VPS
Friktoria.com VPS are not based on Stand Alone Servers, as most providers usually do. The easy solution of Stand Alone Servers solely binds VPS to Servers they run on and their hardware. This poses risks of unavailability of VPS in any failure of the Server or its hardware (eg CPU malfunction, memory malfunction, power supply malfunction, disk malfunction, etc.). At Friktoria.com we have chosen to operate our VPS with Cloud technologies, ie Cluster of Servers. This technology allows our VPS to have High Avaliability, because if one, two or more Servers are down from any damage or failure, then other Servers in the same Cluster retrieve and operate the VPS of the fallen Servers in seconds.

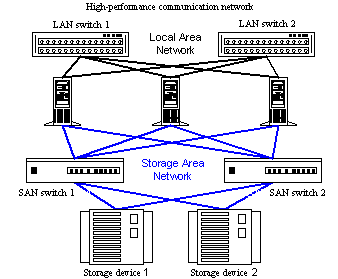
In order our VPS to properly be High Availabile using the above technology, then disks and their files are not located within the same Server that hosts them. This would be an oxymoron, because if that Server crashes, the disks with the files that it hosts will no longer be accessible, as CPU and memory. At Friktoria.com we have chosen to store the disks with the files in a fast Storage Area Network (SAN) dedicated to this purpose. This gives us many possibilities like:
- CPU and memory Servers Operate independently of data.
- We have lots of Petabyte storage space (that is much more space than the largest disk drive on todays market).
- We have a lot of devices in the same network at the same time. e.g. Storage Disks, Data Bases, Backup Systems, etc.
- We have very high communication speeds between the servers (processing power and memory) with the Storage Devices, also the Storage Devices with the Backup systems.
- We can extend the whole system on-line without having Down-Time on our VPS, just by adding Servers and storage devices.

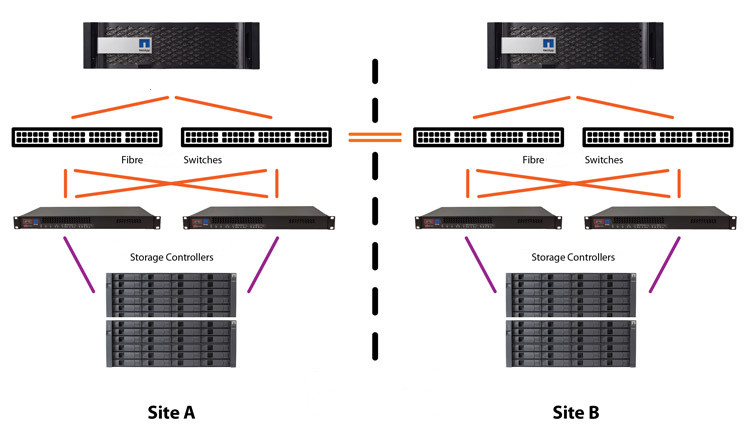
Also at Friktoria.com our SAN does not consist of a single Storage Device and a single Backup System (as other providers with similar technology do). That would be the weakest link, just a single point of failure for the whole SAN, and in failure we will have no data. We have therefore chosen to use a Distributed Storage System technology, the one that has proven effective in large and reliable installations such as Cern. In this technology we operate another cluster of storage servers in which each Server have different storage space (disks). There we cut the data (ie the files) into small pieces, and then we distribute them to multiple Servers at the same time. This exponentially increases the speed of data access, either for writing or for reading. At the same time we keep more copies of those pieces on multiple Servers (at least three copies). This minimizes the likelihood of data being unavailable or lost, even if a Storage Server failure occurs in one or more servers.

But for us, at Friktoria.com, that's not enough either. So we decided to back up the data daily (ie VPS disks) to a separate Dedicated Backup System in the same SAN, holding at least three copies back, to avoid even any possible failure.
To maximize the availability and speed of our SAN to the fullest (and by extension our VPS and other services), we have chosen to use multiple switches, with large throughputs, interconnected to each other and to servers (either Power Servers or Storage Servers). Those switches connect with fiber optics cables at speeds multiplied of 10Gbps (eg 20Gbps, 40Gbps, 60Gbps, 80Gbps, etc.) depending on the connections load.
The next step we are preparing, for even greater availability, security, speed, etc. is to extend our Cluster to a new Data Center in another city, synchronized OnLine in real time.